Here's a Forth program debugged in KDevelop – a graphical debugger without Forth support:
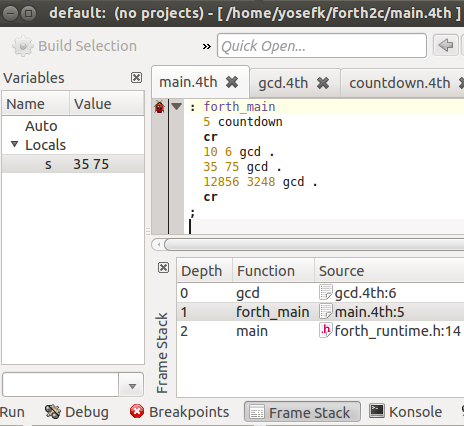
Cool stuff, not? The syntax highlighting for Forth files – that's someone else's work that comes with the standard KDevelop installation. But the rest – being able to run Forth under KDevelop, place breakpoints, and look at program state – all that stuff is something we'll develop below.
I'll show all the required code; we don't have to do very much, because we get a lot for free by using C as an intermediate language.
A high-level intermediate language is not unusual. A lot of compilers target an existing high-level platform instead of generating native code – for instance, by generating JVM bytecode or JavaScript source code. Why? Because of all the things you get for free that way:
- Portability
- Optimization
- Some degree of library interoperability
- Some degree of tools interoperability (IDEs, debuggers, etc.)
A few languages targeting high-level platforms are rather well-known: Scala and Clojure with compilers targeting the JVM, CoffeeScript and Dart which are compiled to JavaScript. (Then there's Java, which Google famously compiles to JavaScript – though that remains somewhat offbeat.)
Which languages of this kind are the most successful? Without doubt, today the answer is C++ and Objective-C – languages whose first compilers emitted C code.
I think C is an awesome intermediate language for a compiler to emit. It's extremely portable, it compiles in a snap, optimizes nicely, and you get interoperability with loads of stuff.
When I wanted to make a compiler for an interpreted language we developed internally, I actually thought about targeting a VM, not a source language. I planned to emit LLVM IR. It was GD who talked me out of it; and really, why LLVM IR?
After all, LLVM IR is less readable than C, less stable than the C standard – and less portable than C. It will likely always be, almost by definition.
Even if LLVM runs on every hardware platform, LLVM IR will only be supported by the LLVM tools – but not, say, the GNU tools, or Visual Studio. Whereas generating C code gives you great support by LLVM tools – and GNU, and Visual Studio. Debugging a program generated from LLVM IR in Visual Studio will probably always be inferior to debugging auto-generated C code compiled by the Visual Studio compiler.
"C as an intermediate language" is one of those things I wanted to write about for years. What prevented me was, I'd like to walk through an example – including some of the extra work that may be required for better debugging support. But I couldn't think of a blog-scale example ("web-scale" seems to be the new synonym for "loads of data"; I propose "blog-scale" to mean "small enough to fully fit into a blog post".)
Then it dawned on me: Forth! The minimalist language I've fallen out of love with that still has a warm place in my heart.
So, I'll do a Forth-to-C compiler. That'll fit in a blog post – at least a small Forth subset will – and Forth is different enough from C to be interesting. Because my point is, it doesn't have to be C with extensions like C++ or Objective-C. It can be something rather alien to C and you'll still get a lot of mileage out of the C tools supplied by your platform.
Without further ado, let's implement a toy Forth-to-C compiler. We shall:
- Define a small Forth subset
- Implement a simple compiler and runtime
- Debug a Forth program using gdb
- Profile a Forth program using KCachegrind
- Display the data stack using gdb pretty-printers
- Debug in KDevelop using the data stack display
Enough Forth to not be dangerous
To be dangerous, we'd have to support CREATE/DOES> or COMPILE or POSTPONE or something of the sort. We won't – we'll only support enough Forth to implement Euclid's GCD.
So here's our Forth subset – you can skip this if you know Forth:
- Forth has a data stack.
- Integers are pushed onto the stack. When you say 2 3, 2 is pushed and then 3.
- Arithmetic operators pop operands from the stack and push the result. 6 2 / pops 6 and 2 and pushes 6/2=3. 2 3 = pushes 0 (false), because 2 is not equal to 3.
- Stack manipulation words, well, manipulate the stack. DUP duplicates the top of the stack: 2 DUP is the same as 2 2. Swap: 2 3 SWAP is the same as 3 2. Tuck: 2 3 TUCK is the same as... errm... 3 2 3. As you can already imagine, code is more readable with less of these words.
- New words are defined with : MYNAME ...code... ; Then if you say MYNAME, you'll execute the code, and return to the point of call when you reach the semicolon. No "function arguments" are declared – rather, code pops arguments from the stack, and pushes results. Say, : SQUARE DUP * ; defines a squaring word; now 3 SQUARE is the same as 3 DUP * – it pops 3 and pushes 9.
- Loops: BEGIN ... cond UNTIL is like do { ... } while(!cond), with cond popped by the UNTIL. BEGIN ... cond WHILE ... REPEAT is like while(1) { ... if(!cond) break; ... }, with cond popped by the WHILE.
- Printing: 2 . prints "2 ". CR prints a newline.
- Forth is case-insensitive.
That's all – enough to implement GCD, and to scare and startle your infix-accustomed friends.
"Compilation strategy"
...A bit too dumb to be called a strategy; anyway, our blog-scale, blog-strength compiler will work as follows:
- The stack is an array of "data"; data is a typedef for long.
- Each user-defined word is compiled to a C function getting a data* pointing to the top of stack (TOS), and returning the new TOS pointer.
- Where possible, built-in words can be used similarly to user-defined words: s=WORD(s).
- Some words can't work that way: + can't become s=+(s) because that's not valid C. For such words, we do some trivial translation. 2 becomes PUSH(2), + becomes OP2(+). Similarly, control flow words are translated to do/while, if and break.
- The stack grows downwards and shrinks upwards: if s[0] is the TOS, s[1] is the element below it, etc; s++ shrinks the stack by popping the TOS.
That's all; for instance, the gcd example from here:
: gcd begin dup while tuck mod repeat drop ;
...compiles to the C code below. As you can see, every word is translated in isolation – the compiler has almost no comprehension of "context" or "grammar":
data* gcd(data* s) { //: gcd
do { //begin
s=dup(s); //dup
if(!*s++) break; //while
s=tuck(s); //tuck
OP2(%); //mod
} while(1); //repeat
s=drop(s); //drop
return s; //;
}
Here's the full Python source of the compiler (forth2c.py) – a bit redundant after all the explanations:
#!/usr/bin/python
import sys
# "special" words - can't emit s=WORD(s)
special = {
':':'data* ',
';':'return s; }',
'.':'PRINT();',
'begin':'do {',
'until':'} while(!*s++);',
'repeat':'} while(1);',
'while':'if(!*s++) break;',
}
# binary operators
binops='+ - * / = < > mod'.split()
op2c={'=':'==','mod':'%'}
def forth2c(inf,out):
n = 0
for line in inf:
n += 1
# emit line info for C tools (debuggers, etc.)
# - a nice option C gives us
print >> out,'\n#line',n,'"%s"'%infile
for token in line.lower().strip().split():
if token in special:
print >> out,special[token],
else:
try:
num = int(token)
print >> out, 'PUSH(%d);'%num,
except ValueError:
if token in binops:
print >> out,'OP2(%s);'%op2c.get(token,token),
else:
if defining:
print >> out,token+'(data* s) {',
else: # call
print >> out,'s=%s(s);'%token,
defining = token == ':'
out = open('forth_program.c','w')
print >> out, '#include "forth_runtime.h"'
for infile in sys.argv[1:]:
forth2c(open(infile),out)
And here's the "runtime library", if you can call it that (forth_runtime.h). It's the kind of stack-fiddling you'd expect: s++, s--, s[0]=something.
#include <stdio.h>
typedef long data;
#define PUSH(item) (--s, *s = (item))
#define OP2(op) (s[1] = s[1] op s[0], ++s)
#define PRINT() (printf("%ld ", s[0]), ++s)
#define cr(s) (printf("\n"), s)
#define drop(s) (s+1)
#define dup(s) (--s, s[0]=s[1], s)
#define tuck(s) (--s, s[0]=s[1], s[1]=s[2], s[2]=s[0], s)
#define MAX_DEPTH 4096 //arbitrary
data stack[MAX_DEPTH];
data* forth_main(data*);
int main() { forth_main(stack+MAX_DEPTH); return 0; }
Note that our Forth dialect has an entry point word – forth_main – that is passed a pointer to an empty stack by C's main. Real Forth doesn't have an entry point – it's more like a scripting language that way; but the forth_main hack will do for our example.
That's all! A Forth dialect in under 60 LOC. By far the shortest compiler I ever wrote, if not the most useful.
A test
Let's test our forth2c using a few example source files. countdown.4th (from here):
: COUNTDOWN
BEGIN
DUP .
1 -
DUP 0 =
UNTIL
DROP
;
gcd.4th (a multi-line version – to make single-stepping easier):
: gcd
begin
dup
while
tuck
mod
repeat
drop
;
main.4th:
: forth_main 5 countdown cr 10 6 gcd . 35 75 gcd . 12856 3248 gcd . cr ;
We can run the program with the shell script:
./forth2c.py countdown.4th gcd.4th main.4th gcc -g -static -Wall -o forth_program forth_program.c ./forth_program
This should print:
5 4 3 2 1 2 5 8
So countdown manages to count down from 5 to 1, and gcd finds the gcd. Good for them.
Debugging
Let's try our program with the trusty gdb:
$ gdb forth_program There is NO WARRANTY!! etc. etc. (gdb) b countdown # place breakpoint Breakpoint 1: file countdown.4th, line 3. (gdb) r # run Breakpoint 1, countdown (s=0x804e03c) at countdown.4th:3 (gdb) bt # backtrace #0 countdown (s=0x804e03c) at countdown.4th:3 #1 forth_main (s=0x804e03c) at main.4th:2 #2 main () at forth_runtime.h:14 (gdb) l # list source code 1 : COUNTDOWN 2 BEGIN 3 DUP . 4 1 - 5 DUP 0 = 6 UNTIL 7 DROP 8 ; (gdb)
Yay!!
Seriously, yay. We placed a breakpoint. We got a call stack – forth_main called countdown. And we've seen the Forth source code of the function we debug. All that in a debugger that has no idea about Forth.
Partly it's due to compiling to high-level primitives, such as functions, that are supported by tools – we'd get that in every language. And partly it's due to #line – something we don't get everywhere.
#line is brilliant – all languages should have it. That's how we tell debuggers where our assembly code is really coming from – not the intermediate C code, but the real source.
Profilers and other tools
It's not just debuggers that understand #line – it's also profilers, program checkers, etc.
Here's KCachegrind showing the profile of our Forth program, obtained using Valgrind as follows:
valgrind --tool=callgrind ./forth_program kcachegrind `ls -t callgrind* | head -1`
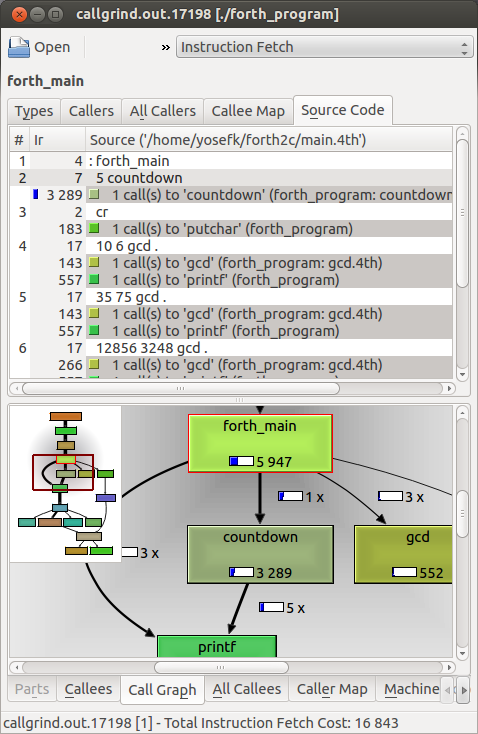
Now isn't that spiffy?
C compilers are also aware of #line – which we could try to abuse by pushing error reporting onto the C compiler. Say, if we use an undefined word do_something, we get an error at just the right source code line:
main.4th:3: implicit declaration of function ‘do_something’
A very sensible error message – and we didn't have to do anything! Now let's try a BEGIN without a REPEAT – let's delete the REPEAT from countdown.4th:
gcd.4th:1: error: expected ‘while’ before ‘data’
Um, not a very good message. Perhaps this isn't such a good idea after all. If we want quality error reporting, we have to do the error checking at the source language level.
Custom data display: gdb pretty-printers
Things look rather nice. C tools – gdb, Valgrind, KCachegrind – are doing our bidding, aren't they?
Except for the data stack. Instead of the stack elements, gdb shows us the TOS pointer in hexadecimal: countdown (s=0x804e03c), forth_main (s=0x804e03c), which looks a bit lame.
It's not that the local variable s is useless – on the contrary, that's what we use to look at the data stack. This can be done using gdb commands such as p s[0] (prints the TOS), p s[1] (prints the element below TOS), etc. But we'd much rather look at the whole stack at a time, so that we can see how TUCK tucks our numbers into the stack as we single-step our code.
Can it be done?
- The good news are that it's easy enough with gdb pretty-printers. (To me it became easy after Noam told me about the pretty-printers.)
- The bad news are that, unlike the case with the universally supported #line, it's impossible to do custom pretty-printing in a uniform way for all tools. There's no "#line for pretty-printing" – quite a pity.
- But then the good news are that gdb front-ends such as KDevelop or Eclipse support gdb pretty-printers – to an extent. (KDevelop apparently does a better job than Eclipse.) So you don't have to write a GUI plugin or something equally horrible.
Here's a gdb pretty printer for displaying our Forth data stack. It prints all the elements, from bottom to top (as the Forth stack contents is usually spelled). The TOS pointer is the data* you pass for printing – typically, some function's local variable s. The bottom of the stack is known statically – it's the pointer past the end of the global stack[] array. (If we had threads, that array would be thread-local, but anyway, you get the idea.)
So here's gdb_forth.py:
class StackPrettyPrinter(object):
bottom = None
bot_expr = 'stack + sizeof(stack)/sizeof(stack[0])'
def __init__(self,s):
self.s = s
def to_string(self):
if not self.bottom:
self.bottom = gdb.parse_and_eval(self.bot_expr)
s = self.s
i = 0
words = []
while s[i].address != self.bottom:
words.append(str(s[i]))
i += 1
return ' '.join(reversed(words))
def stack_lookup_func(val):
if str(val.type) == 'data *':
return StackPrettyPrinter(val)
gdb.pretty_printers.append(stack_lookup_func)
print 'loaded Forth extensions'
gdb.pretty_printers is a list of functions which may decide to wrap gdb.Value they're passed in a pretty-printer class object. Typically they decide based on the value's type. gdb.parse_and_eval returns a gdb.Value representing the value of the given C expression. A gdb.Value has a type, an address, etc. If the gdb.Value is a pointer, you can index it as a Python list: val[ind], and if it's a struct, you can use it as a dict: val['member_name'] (we don't have an example of that one here).
If you're interested in gdb pretty printers – a couple of notes:
- Getting values from other values is much faster than parse_and_eval which just grinds the CPU to a halt; so learning the not-that-Pythonic-while-also-not-that-C-like syntax of gdb.Value access is very worthwhile.
- You can return "maps" or "arrays" instead of plain strings. Pretty-printers for STL maps and vectors work that way. This can be used to pretty-print high-level data structures such as dynamic objects (if you're lucky and your design matches gdb's view of things – I found a lot of devil in the details.)
Let's test-drive our pretty printer – but first, let's register it in our ~/.gdbinit:
python execfile('/your/path/to/gdb_forth.py')
And now:
$ gdb forth_program There is NO WARRANTY!! loaded Forth extensions # aha, that's our printout! (gdb) b gcd (gdb) r Breakpoint 1, gcd (s=10 6) # and that's the stack (gdb) python for i in range(4): gdb.execute('c') # continue 4 times Breakpoint 1, gcd (s=6 4) Breakpoint 1, gcd (s=4 2) Breakpoint 1, gcd (s=2 0) # these were the steps of gcd(10,6) Breakpoint 1, gcd (s=35 75) 3 dup # new inputs - gcd(35,75). let's single-step: (gdb) s # step (execute DUP) 4 while (gdb) p s # print s $1 = 35 75 75 # so DUP duplicated the 75. (gdb) s # step (execute WHILE) 5 tuck (gdb) p s $2 = 35 75 # ...and WHILE popped that 75. (gdb) s # and now we execute the mighty TUCK: 6 mod (gdb) p s $3 = 75 35 75 # YES! Tucked the 75 right in! (gdb) bt # and how's main's data stack looking? #0 gcd (s=75 35 75) at gcd.4th:6 #1 forth_main (s=75 35) at main.4th:5 # well, it looks shorter - somewhat sensibly. # (main TOS pointer is unchanged until gcd returns.)
I think it's rather nice. 10 6, 6 4, 4 2, 2 0 – a concise enough walk through Euclid's algorithm in Forth.
KDevelop with the stack display
And, finally, here's how it looks in KDevelop (where the stack displayed in the GUI changes upon every step, as one would expect from a good debugger). The stack is in the variables view on the left.
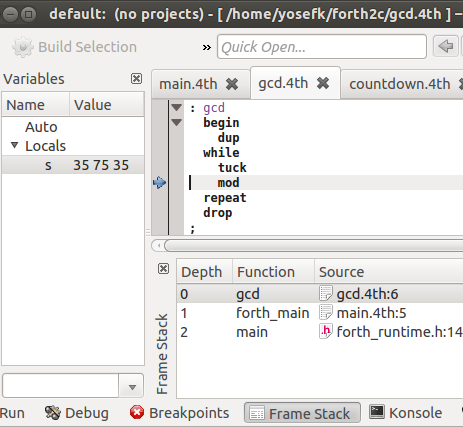
There is nothing special to be done to make things work in KDevelop – except for the standard procedure of convincing it to debug a user-supplied executable, as you might do with a C program.
Features that don't map naturally to C
Some features of a source language map more naturally to C than others. If we tried to tackle a language different from Forth – or to tackle all of Forth instead of a small subset – some features would pose hard problems.
Some such features can be handled straightforwardly with another intermediate language. For example, dynamic data attributes map to JavaScript much more nicely than they do to C.
But in many cases you don't pick your intermediate language because it's the most suitable one for your source language. If you want to target browsers, then it pretty much has to be JavaScript, even if it's a poor fit for your source language. Similarly, in other situations, it has to be C – or JVM, or .NET, etc.
In fact, many language designers made it their key constraint to play nicely with their platform – the intermediate language. Some advertise the harmonious integration with the platform in the language name: C++, Objective-C, CoffeeScript, TypeScript. They know that many users are more likely to choose their language because of its platform than for any other reason, because they're locked into the platform.
With that said, here are a few features that don't map straightforwardly to C, and possible ways to handle them.
- Dynamic binding: easy enough. Generate something like call(object,method_id), or call(object,"method_name"), multidispatch(method,obj1,obj2) – whatever you want. Should work nicely.
- Dynamic code generation – eval, etc.: C doesn't have eval – but it does have fopen("tmp.c"), fwrite, system("gcc -o tmp.so tmp.c ..."), dlopen("tmp.so"), and dlsym. This can give you something a lot like eval. You need non-portable code to make it work, but not much of it. Alternatively, if a relatively slow eval with relatively poor debugger support is OK (often it is), you can implement eval using an interpreter, which can reuse the parser of your static compiler. We use both methods in a few places and it works fine.
- Dynamic data: Code generation is easy – access(object,"attr_name") or whatever. The ugly part is viewing these objects in debuggers. One approach is pretty-printers or similar debugger scripting. Another approach – for "static enough data" – is to generate C struct definitions at runtime, compile them to a shared library with debug info, and load the library, as you'd do to implement eval.
- Exceptions: I use setjmp/longjmp for that; I think that's what cfront did.
- Garbage collection: AFAIK it can work fine, funnily enough. There are garbage collectors for C, such as the Boehm collector. Do they work for C programs? Not really – they can mistake a byte pattern that happens to look like a pointer for an actual pointer, causing a leak. But you don't have that problem – because your C program is generated from code that your compiler can analyze and then tell the collector where to look for pointers. So while gc doesn't truly work for C, it can work fine for languages implemented on top of C!
- Generics, overloading, etc.: most of this is handled by your compiler, the only problem being name mangling. You can mangle names in a way that you find least ugly, or you can mangle them according to the C++ mangling convention, so that debuggers then demangle your names back into collection<item> or some such. (The C++ mangling convention is not portable so you might need to support several.)
- Multiple return values: we pass pointers to all return values except the first; I think returning a struct might make things look nicer in debuggers. Of course the calling convention will be less efficient compared to a compiler emitting assembly rather than C. But it will still be more efficient than your actual competition, such as a Python tuple.
- Program reduction (as in, transform (+ (* 2 3) 5) to (+ 6 5), then to 11): ouch. I guess it could make sense to write an interpreter to do that in C, but you wouldn't get that much mileage out of the C optimizer, and no mileage at all from C debuggers, profilers, etc. The basic model of computation has to be close enough to C to gain something from the C toolchain besides the portability of your C code implementing your language. (I'm not saying that you absolutely have to create a memory representation of (+ 6 5) at runtime – just that if you want to create it, then C tools won't understand your program.)
What about using C++ instead of C?
You could, and I did. I don't recommend it. You get exceptions for free instead of fiddling with setjmp/longjmp. Then they don't work when you throw them from one shared library and catch in another (I think RTTI has similar problems with shared libraries). You get templates for free. Then your auto-generated code compiles for ages.
Eli Bendersky writes about switching from C to C++ to implement a language VM. He says it's easier to use C++ features when they match your VM's needs then to reimplement them in C.
Here's how it worked out for me. I once implemented a VM and an interpreter in C++. Then we wrote a compiler for the language. Because the VM was in C++, it was much easier for the compiler to emit C++ code interfacing with the VM than C code. And then with this auto-generated C++ code, we bumped into shared-library-related problems, and build speed problems, etc. – and we have them to this day.
But of course, YMMV. One reason to use C++ is that debuggers get increasingly better at displaying STL collections and base class object pointers (which they know to downcast to the real runtime type and show the derived class members). If your language constructs map to these C++ features, you can get better debug-time data display in a portable way.
Anything you'd like to add?
If you have experience with using C as an intermediate language, I'll gladly add your comments. I'm more experienced with some things than others in this department, and so a lot of the potential issues would likely never occur to me.
Conclusion
C is a great intermediate language, and I'd be thrilled to see more new languages compiling to C. I don't live in either Java or JavaScript these days; surely I'm not alone. A language compiling to C could be fast, portable, have nice tools and library support – and immediately usable to many in the land of C, C++ and Objective-C.