There are many potential ways to use AI1 (and computers in general) for 2D animation. I’m currently interested in a seemingly conservative goal: to improve the productivity of a traditional hand-drawn full animation workflow by AI assuming responsibilities similar to those of a human assistant.
As a “sub-goal” of that larger goal, we’ll take a look at two recently published papers on animation “inbetweening” – the automatic generation of intermediate frames between given keyframes. AFAIK these papers represent the current state of the art. We’ll see how these papers and a commercial frame interpolation tool perform on some test sequences. We’ll then briefly discuss the future of the broad family of techniques in these papers versus some substantially different emerging approaches.
There’s a lot of other relevant research to look into, which I’m trying to do - this is just the start. I should say that I’m not “an AI guy” - or rather I am if you’re building an inference chip, but not if you’re training a neural net. I’m interested in this as a programmer who could incorporate the latest tech into an animation program, and as an animator who could use that program. But I’m no expert on this, and so I’ll be very happy to get feedback/suggestions through email or comments.
I’ve been into animation tech since forever, and what’s possible these days is exciting. Specifically with inbetweening tech, I think we’re still “not there yet”, and I think you’ll agree after seeing the results below. But we might well get there within a decade, and maybe much sooner.
I think this stuff is very, very interesting! If you think so, too, we should get in touch. Doubly so if you want to work on this. I am going to work on exactly this!
Motivation and scope
Why is it interesting to make AI a 2D animator’s assistant, of all the things we could have it do (text to video, image to video, image style transfer onto a video, etc.)?
- An animator is an actor. The motion of a character reflects the implied physical and mental state of that character. If the motion of a character, even one designed by a human, is fully machine-generated, it means that human control over acting is limited; the machine is now the actor, and the human’s influence is limited to “directing” at best. It is interesting to develop AI-assisted workflows where the human is still the actor.
- To control motion, the animator needs to draw several keyframes (or perhaps edit a machine-generated draft - but with a possibility to erase and redraw it fully.) The range of ways to do “a sad walk” or “an angry, surprised head turn” and the range of character traits influencing the acting is too wide for acting to be controlled via cues other than actually drawing the pose.
- If a human is to be in control, “moving line art” is the necessary basis for any innovations in the appearance of the characters. That’s because humans use a “light table”, aka “onion skin”, to draw moving characters, where you see several frames overlaid on top of each other (like the frames of a bouncing ball sequence below). And it’s roughly not humanly possible to “read” a light table unless the frames have the sharp edges of line art (believe me, I spent more time trying than I should have.) Any workflow with human animators in control of motion needs to have line art at its basis, even if the final rendered film looks very differently from the traditional line art style.

- The above gives the human a role similar to a traditional key animator, so it’s natural to give the machine the roles of assistants. It could be that AI can additionally do some of the key animator’s work, so that less keyframes are provided in some cases than you’d have to give a human assistant (and one reason for this could be your ability to quickly get the AI to complete your work in 10-20 possible ways, and choose the best option, which is impractical with a human assistant.) But the basic role of the human as a key animator would remain, and so the first thing to explore is the machine taking over the assistant’s role.
So I’m not saying that we can’t improve productivity beyond the “machine as the assistant” arrangement, nor that we must limit ourselves to the traditional appearance of hand-drawn animation. I’m just saying that our conservative scope is likely the right starting point, even if our final goals are more ambitious - at least as long as we want the human to remain the actor.
What would the machine do in an assistant’s role? Traditionally, assistants’ jobs include:
- Inbetweening (drawing frames between the key frames)
- Cleanup (taking rough “pencil” sketches and “inking” them)
- Coloring (“should” be trivial with a paint bucket tool, but surprisingly annoying around small gaps in the lines)
Our scope here is narrowed further by focusing exclusively on inbetweening. There’s no deep reason for this beyond having to start somewhere, and inbetweening being the most “animation-y” assistant’s job, because it’s about movement. So focusing our search on inbetweening is most likely to give results relevant to animation and not just “still” line art.
Finally, in this installment, we’re going to focus on papers which call themselves “AI for animation inbetweening” papers. It’s not obvious that any relevant “killer technique” has to come from a paper focusing on this problem explicitly. We could end up borrowing ideas from papers on video frame interpolation, or video/animation generation not designed for inbetweening, etc. In fact, I’m looking at some things like this. But again, let’s start somewhere.
Preamble: testing Runway
Before looking at papers for the latest ideas, let’s check out Runway Frame Interpolation. Together with Stability AI and the CompVis group, Runway researchers were behind Stable Diffusion, and Runway is at the forefront of deploying generative AI for video.
Let’s test frame interpolation on a sneaky cartoony rabbit sequence. It’s good as a test sequence because it has both fast/large and slower/smaller movement (so both harder and easier parts.) It also has both “flat 2D” body movement and “3D” head rotation - one might say too much rotation… But rotation is good to test because it’s a big reason for doing full hand-drawn animation. Absent rotation, you can split your character into “cut-out” parts, and animate it by moving and stretching these parts.

We throw away every second frame, ask Runway to interpolate the sequence, and after some conversions and a frame rate adjustment (don’t ask), we get something like this:

This tool definitely isn’t currently optimized for cartoony motion. Here’s an example inbetween:

Now let’s try a similar sequence with a sneaky me instead of a sneaky rabbit. Incidentally, this is one of several styles I’m interested in - something between live action and Looney Tunes, with this self-portrait taking live action maybe 15% towards Looney Tunes:

Frame interpolation looks somewhat better here, but it’s still more morphing than moving from pose to pose:

An example inbetween:

While the Frame Interpolation tool currently doesn’t work for this use case, I’d bet that Runway could solve the problem quicker and better than most if they wanted to. Whether there’s a large enough market for this is another question, and it might depend on the exact definition of “this.” Personally, I believe that a lot of good things in life cannot be “monetized”, a lot of art-related things are in this unfortunate category, and I’m very prepared to invest time and effort into this without clear, or even any prospects of making money.
In any case, we’ve got our test sequences, and we’ve got our motivation to look for better performance in recent papers.
Raster frame representation
There’s a lot of work on AI for image processing/computer vision. It’s natural to borrow techniques from this deeply researched space and apply them to line art represented as raster images.
There are a few papers doing this; AFAIK the state of the art with this approach is currently Improving the Perceptual Quality of 2D Animation Interpolation (2022). Their EISAI GitHub repo points to a colab demo and a Docker image for running locally, which I did, and things basically Just Worked.
That this can even happen blows my mind. I remember how things worked 25 years ago, when you rarely had the code published, and people implementing computer vision papers would occasionally swear that the paper is outright lying, because the described algorithms don’t do and couldn’t possibly do what the paper says.
The sequence below shows just inbetweens produced by EISAI. Meaning, frame N is produced from the original frames N-1 and N+1; there’s not a single original frame here. So this sequence isn’t directly comparable to Runway’s output.

I couldn’t quite produce the same output with Runway as with the papers (don’t ask.) If you care, this sequence is closer to being comparable to Runway’s, if not fully apples to apples:

If you look at individual inbetweens, you’ll see that EISAI and Runway have similar difficulties - big changes between frames, occlusion and deformation, and both do their best and worst in about the same places. One of the best inbetweens by EISAI:

One of the worst:

The inbetweens are produced by forward-warping based on bidirectional flow estimation. “Flow estimation” means computing, per pixel or region in the first keyframe, its most likely corresponding location in the other keyframe - “finding where it went to” in the other image (if you have “two images of mostly the same thing,” you can hope to find parts from one in the other.) “Warping” means transforming pixel data - for example, scaling, translating and rotating a region. “Forward-warping by bidirectional flow estimation” means taking regions from both keyframes and warping them to put them “where they belong” in the inbetween - which is halfway between a region’s position in the source image, and the position in the other image that the flow estimation says this region corresponds to.
Warping by flow explains the occasional 3-4 arms and legs and 2 heads (it warps a left hand from both input images into two far-away places in the output image, since the flow estimator found a wrong match, instead of matching the hands to each other.) This also explains “empty space” patches of various sizes in the otherwise flat background.
Notably, warping by flow “gives up” on cases of occlusion up front (I mean cases where something is visible in one frame and not in the other due to rotation or any other reason.) If your problem formulation is “let’s find parts of one image in the other image, and warp each part to the middle position between where it was in the first and where we found it in the second” - then the correct answer to “where did the occluded part move?” is “I don’t know; I can’t track something that isn’t there.”
(Note that the system being an “AI” has no impact on this point. You could have a “traditional,” “hardcoded” system for warping based on optical flow, or a differentiable one with trainable parameters (“AI”.) Let’s say we believe the trainable one is likely to achieve better results. But training does not sidestep the question the parameters of what are being trained, and what the model can, or can’t possibly do once trained.)
When the optical flow matches “large parts” between images correctly, you still have occasional issues due to both images being warped into the result, with “ghosting” of details of fingers or noses or what-not (meaning, you see two slightly different drawings of a hand at roughly the same place, and you see one drawing through the other, as if that other drawing was a semi-transparent “ghost”.) A dumb question coming to my mind is if this could be improved through brute force, by “increasing the resolution of the image” / having a “higher-resolution flow estimation,” so you have a larger number of smaller patches capable of representing the deformations of details, because each patch is tracked and warped separately.
An interesting thing in this paper is the use of distance transform to “create” texture for convolutional neural networks to work with for feature extraction. The distance transform replaces every pixel value with the distance from that pixel’s coordinates to the closest black pixel. If you interpret distances as black & white pixel values, this gives “texture” to your line art in a way. The paper cites “Optical flow based line drawing frame interpolation using distance transform to support inbetweenings” (2019) which also used distance transform for this purpose.
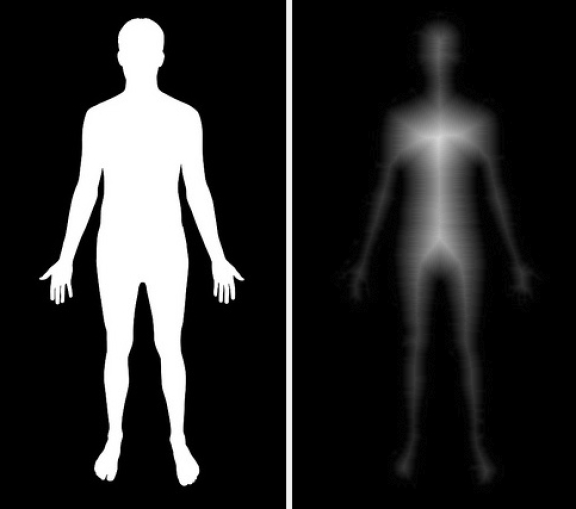
If you’re dealing with 2D animation and you’re borrowing image processing/computer vision neural networks (hyperparameters and maybe even pretrained weights, as this paper does with a few layers of ResNet), you will have the problem of “lack of texture” - you have these large flat-color regions, and the output of every convolution on each pixel within the region is obviously exactly the same. Distance transform gives some texture for the convolutions to “respond” to.
This amuses me in a “machine learning inside joke” sort of way. “But they told me that manual feature engineering was over in the era of Deep Learning!” I mean, sure, a lot of it is over - you won’t see a paper on “the next SIFT or HOG.” But, apart from the “hyperparameters” (a name for, basically, the entire network architecture) being manually engineered, and the various manual data augmentation and what-not, what’s Kornia, if not “a tool for manual feature engineering in a differentiable programming context”? And I’m not implying that there’s anything wrong with it - quite the contrary, my point is that people still do this because it works, or at least makes some things work better.
Before we move on to other approaches, let’s check how EISAI does on the rabbit sequence. I don’t care for the rabbit sequence; I’m selfishly interested in the me sequence. But since unlike Runway, EISAI was trained on animation data, it seems fair to feed it something more like the training data:

Both Runway and EISAI do worse on the rabbit, which has more change in hands and ears and walks a bit faster. It seems that large movements, deformations and rotations affect performance more than “similarity to training data,” or at least similarity in a naive sense.
Vector frame representation
Instead of treating the input as images, you could work on a vector representation of the lines. AFAIK the most recent paper in this category is Deep Geometrized Cartoon Line Inbetweening (2023). Their AnimeInbet GitHub repo lets you reproduce the paper’s results. To run on your own data, you need to hack the code a bit (at least I didn’t manage without some code changes.) More importantly, you need to vectorize your input data somehow.
The paper doesn’t come with its own input drawing vectorization system, and arguably shouldn’t, since vector drawing programs exist, and vectorizing raster drawings is a problem in its own right and outside the paper’s scope. The code in the paper has no trouble getting input data in a vector representation because their line art dataset is produced from their dataset of moving 3D characters, rendered with a “toon shader” or whatever the thing rendering lines instead of shaded surfaces is called. And since the 2D points/lines come from 3D vertices/edges, you’re basically projecting a 3D vector representation into a 2D space and it’s still a vector representation.
What’s more, this data set provides a kind of ground truth that you don’t get from 2D animation data sets - namely, detailed correspondence between the points in both input frames and the ground truth inbetween frame. If your ground truth is a frame from an animated movie, you only know that this frame is “the inbetween you expect between the previous frame and the next.” But here, you know where every 3D vertex ended up in every image!
This correspondence information is used at training time - and omitted at inference time, or it would be cheating. So if you want to feed data into AnimeInbet, you only need to vectorize this data into points connected by straight lines, without worrying about vertex correspondence. The paper itself cites Virtual Sketching, itself a deep learning based system, as the vectorization tool they used for their own experiments in one of the “ablation studies” (I know it’s idiomatic scientific language, but can I just say that I love this expression? “Please don’t contribute to the project during the next month. We’re performing an ablation study of individual productivity. If the study proves successful, you shall be ablated from the company by the end of the month.”)
There are comments in the AnimeInbet repo about issues using Virtual Sketching; mine was that some lines partially disappeared (could be my fault for not using it properly.) I ended up writing some neanderthal-style image processing code skeletonizing the raster lines, and then flood-filling the skeleton and connecting the points while flood-filling. I’d explain this at more length if it was more than a one-off hack; for what it’s worth, I think it’s reasonably correct for present purposes. (My “testing” is that when I render my vertices and the lines connecting them and eyeball the result, no obviously stupid line connecting unrelated things appears, and no big thing from the input raster image is clearly missing.)
This hacky “vectorization” code (might need more hacking to actually use) is in Animation Papers GitHub repo, together with other code you might use to run AnimeInbet on your data.
Results on our test sequences:

The rabbit is harder for AnimeInbet, similarly to the others. For example, the ears are completely destroyed by the head turn, as usual:
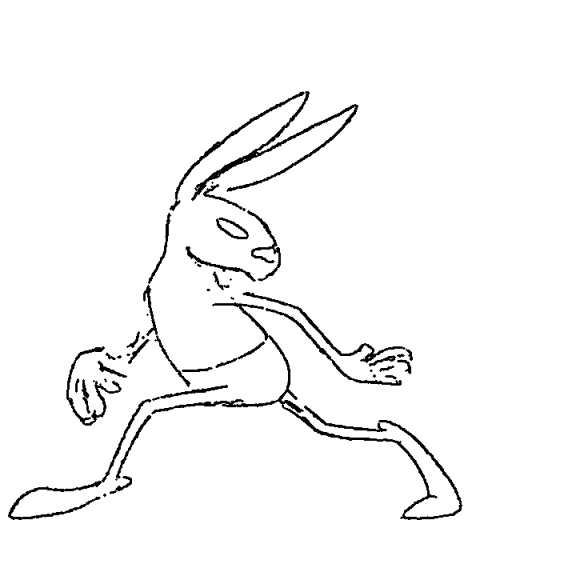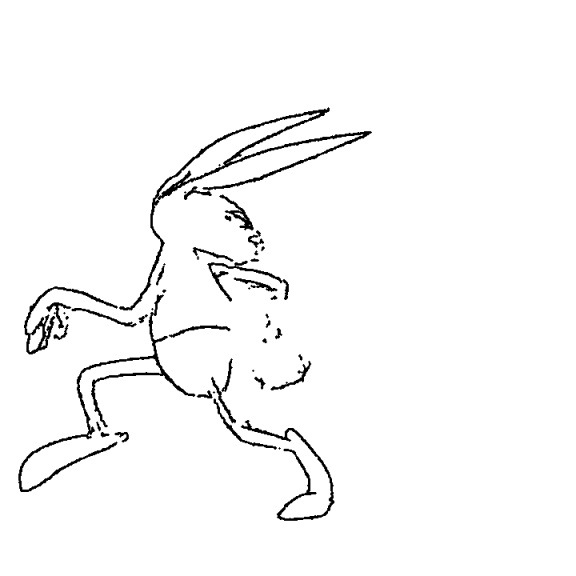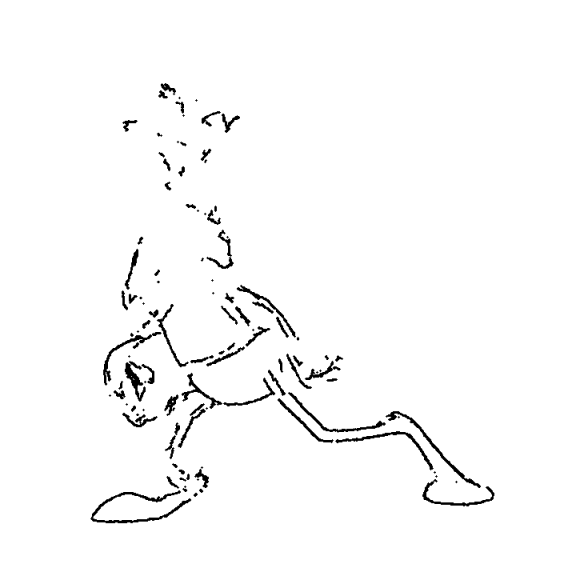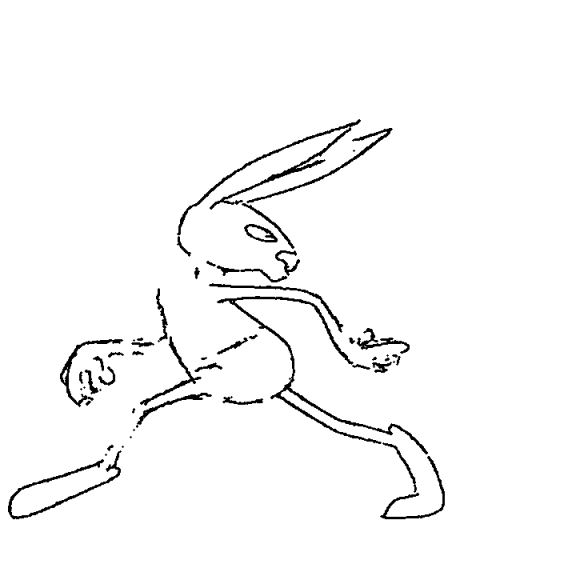
The worst and the best inbetweens occur in pretty much the same frames:
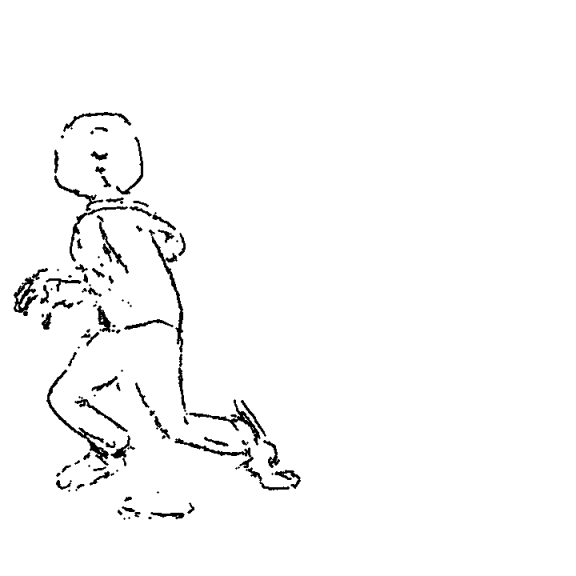

Visually notable aspects of AnimeInbet’s output compared to the previous systems we’ve seen:
- AnimeInbet doesn’t blur lines. It might shred lines on occasion, but you don’t blur vector lines like you blur pixels. (You very much can put a bunch of garbage lines into the output, and AnimeInbet is pretty good at not doing that, but this capability belongs to our next item. Here we’ll just note that raster-based systems didn’t quite “learn” to avoid line blurring, which this system avoids by design.)
- AnimeInbet seems quite good at matching small details and avoiding ghosting/copying the same thing twice from both images. This is not something that can salvage bad inbetweens, but it makes good inbetweens better; in the one above, the pants and the hands are examples where small detail is matched better than in the raster systems.
- For every part, AnimeInbet either finds a match or removes it from the output. The paper formulates inbetweening as a graph matching problem (where vertices are the nodes and the lines connecting them are edges.) Parts without a match are marked as invisible. This doesn’t “solve” occlusion or rotation, but it tends to keep you from putting stuff into the output that the animator needs to erase and redraw afterwards. This makes good inbetweens marginally better; for bad inbetweens, it makes them “less funny” but probably not much more usable (you get 2 legs instead of 4, but they’re often not the right legs; and you can still get a head with two foreheads as in the bad inbetween above.)
AnimeInbet has a comprehensive evaluation of their system vs other systems (EISAI and VFIformer as well as FILM and RIFE, video interpolation rather than specifically animation inbetweening systems.) According to their methodology (where they use their own test dataset), their system comes out ahead by a large margin. In my extremely small-scale and qualitative testing, I’d say that it looks better, too, though perhaps less dramatically.
Here we have deep learning with a model and input data set tailored carefully to the problem - something I think you won’t see as often as papers reusing one or several pretrained networks, and combining them with various adaptations to apply to the problem at hand. My emotional reaction to this approach appearing to do better than ideas borrowed from “general image/video AI research” is mixed.
I like “being right” (well, vaguely) about AI not being “general artificial intelligence” but a set of techniques that you need to apply carefully to build a system for your needs, instead of just throwing data into some giant general-purpose black box - this is something I like going on about, maybe more than I should given my level of understanding. As a prospective user/implementer looking for “the next breakthrough paper,” however, it would be better for me if ideas borrowed from “general video research” worked great, because there’s so many of them compared to the volume of “animation-focused research.”
I mean, Disney already fired its hand-drawn animation department years ago. If the medium is to be revived (and people even caring about it aren’t getting any younger), it’s less likely to happen through direct investment into animation than as a byproduct of other, more profitable things. I guess we’ll see how it goes.
Applicability of “2D feature matching” techniques
No future improvement of the techniques in both papers can possibly take care of “all of inbetweening,” because occlusion and rotation happen a lot, and do not fit these papers’ basic approach of matching 2D features in the input frames. And even the best inbetweens aren’t quite usable as is. But they could be used with some editing, and it could be easier to edit them than draw the whole thing from scratch.
An encouraging observation is that machines struggle with big changes and people struggle with small changes, so they can complement each other well. A human is better at (and less bored by) drawing an inbetween between two keyframes which look very different than drawing something very close to both input frames and putting every line at juuuuust the right place. If machines can help handle the latter kind of work, even with some editing required, that’s great!
It’s very interesting to look into approaches that can in fact handle more change between input frames. For example, check out the middle frame below, generated from the frames on its left and right:

This is from Explorative Inbetweening of Time and Space (2024); they say the code is coming soon. It does have some problems with occlusion (look at the right arm in the middle image.) But it seems to only struggle when showing something that is occluded in both input frames (for example, the right leg is fine, though it’s largely occluded in the image on the left.) This is a big improvement over what we’ve seen above, or right below (this is one frame of Runway’s output, where one right leg slowly merges into the left leg, while another right leg is growing):

But what’s even more impressive - extremely impressive - is that the system decided that the body would go up before going back down between these two poses! (Which is why it’s having trouble with the right arm in the first place! A feature matching system wouldn’t have this problem, because it wouldn’t realize that in the middle position, the body would go up, and the right arm would have to be somewhere. Struggling with things not visible in either input keyframe is a good problem to have - it’s evidence of knowing these things exist, which demonstrates quite the capabilities!)
This system clearly learned a lot about three-dimensional real-world movement behind the 2D images it’s asked to interpolate between. Let’s call approaches going in this direction “3D motion reconstruction” techniques (and I apologize if there’s better, standard terminology / taxonomy; I’d use it if I knew it.)
My point here, beyond eagerly waiting for the code in this paper, is that feature matching techniques might remain interesting in the long term, precisely because “they don’t understand what’s going on in the scene.” Sure, they clearly don’t learn “how a figure moves or looks like.” But this gives some hope that what they can do - handling small changes - will work on more kinds of inputs. Meaning, a system that “learned human movement” might be less useful for an octopus sequence than a system that “learned to match patches of pixels, or graphs of points connected by lines.” So falling back on 2D feature matching could remain useful for a long time, even once 3D motion reconstruction works great on the kinds of characters it was trained on.
Conclusion
I think we can agree that animation inbetweening doesn’t quite work at the moment, though it might already be useful for inbetweening small movements, which is otherwise a painstaking process for a human. I think we can also agree that it’s reasonable to hope it will be production-ready quite soon, and emerging inbetweening systems which “understand and reconstruct movement,” beyond “matching image features,” are one reason to be hopeful.
In future installments, I hope to look into more techniques for inbetweening, and the closely related question of what animators need to control inbetweening, beyond just giving the system two keyframes. Human inbetweeners certainly get more input than pairs of keyframes. This makes me believe that it’s not just the plausibility of the inbetweens you produce, but their controllability which is going to determine “the winning technique.”
Thanks to Dan Luu for reviewing a draft of this post.