We're going to speed up some numpy code by 100x using "unsafe Python." Which is not quite the same as unsafe Rust, but it's a bit similar, and I'm not sure what else to call it... you'll see. It's not something you'd use in most Python code, but it's handy on occasion, and I think it shows "the nature of Python” from an interesting angle.
So let's say you use pygame to write a simple game in Python.
(Is pygame the way to go today? I'm not the guy to ask; to its credit, it has a very simple screen / mouse / keyboard APIs, and is quite portable because it's built on top of SDL. It runs on the major desktop platforms, and with a bit of fiddling, you can run it on Android using Buildozer. In any case, pygame is just one real-life example where a problem arises that "unsafe Python" can solve.)
Let us furthermore assume that you're resizing images a lot, so you want to optimize this. And so you discover the somewhat unsurprising fact that OpenCV's resizing is faster than pygame's, as measured by the following simple microbenchmark:
from contextlib import contextmanager
import time
@contextmanager
def Timer(name):
start = time.time()
yield
finish = time.time()
print(f'{name} took {finish-start:.4f} sec')
import pygame as pg
import numpy as np
import cv2
IW = 1920
IH = 1080
OW = IW // 2
OH = IH // 2
repeat = 100
isurf = pg.Surface((IW,IH), pg.SRCALPHA)
with Timer('pg.Surface with smoothscale'):
for i in range(repeat):
pg.transform.smoothscale(isurf, (OW,OH))
def cv2_resize(image):
return cv2.resize(image, (OH,OW), interpolation=cv2.INTER_AREA)
i1 = np.zeros((IW,IH,3), np.uint8)
with Timer('np.zeros with cv2'):
for i in range(repeat):
o1 = cv2_resize(i1)
This prints:
pg.Surface with smoothscale took 0.2002 sec np.zeros with cv2 took 0.0145 sec
Tempted by the nice 13x speedup reported by the mircobenchmark, you go back to your game, and use
pygame.surfarray.pixels3d to get zero-copy access to the pixels as a numpy array. Full of hope, you pass this array
to cv2.resize, and observe that everything got much slower. Dammit! "Caching," you think, "or something.
Never trust a mircobenchmark!"
Anyway, just in case, you call cv2.resize on the pixels3d array in your mircobenchmark. Perhaps the slowdown will reproduce?..
i2 = pg.surfarray.pixels3d(isurf)
with Timer('pixels3d with cv2'):
for i in range(repeat):
o2 = cv2_resize(i2)
Sure enough, this is very slow, just like you saw in your larger program:
pixels3d with cv2 took 1.3625 sec
So 7x slower than smoothscale - and more shockingly, almost 100x slower than cv2.resize called with numpy.zeros! What gives?! Like, we have two zero-initialized numpy arrays of the same shape and datatype. And of course the resized output arrays have the same shape & datatype, too:
print('i1==i2 is', np.all(i1==i2))
print('o1==o2 is', np.all(o1==o2))
print('input shapes', i1.shape,i2.shape)
print('input types', i1.dtype,i2.dtype)
print('output shapes', o1.shape,o2.shape)
print('output types', o1.dtype,o2.dtype)
Just like you'd expect, this prints that everything is the same:
i1==i2 is True
o1==o2 is True
input shapes (1920, 1080, 3) (1920, 1080, 3)
input types uint8 uint8
output shapes (960, 540, 3) (960, 540, 3)
output types uint8 uint8How could a function run 100x more slowly on one array relatively to the other, seemingly identical array?.. I mean, you would hope SDL wouldn't allocate pixels in some particularly slow-to-access RAM area - even though it theoretically could do stuff like that, with a little help from the kernel (like, create a non-cachable memory area or something.) Or is the surface stored in GPU memory and we're going thru PCI to get every pixel?!.. It doesn't work this way, does it? - is there some horrible memory coherence protocol for these things that I missed?.. And if not - if it's the same kind of memory of the same shape and size with both arrays - what's different that costs us a 100x slowdown?..
It turns out... And I confess that I only found out by accident, after giving up on this1 and moving on to something else. Entirely incidentally, that other thing involved passing numpy data to C code, so I had to learn what this data looks like from C. So, it turns out that the shape and datatype aren't all there is to a numpy array:
print('input strides',i1.strides,i2.strides)
print('output strides',o1.strides,o2.strides)
Ah, strides. Same in the output arrays, but very different in the input arrays:
input strides (3240, 3, 1) (4, 7680, -1) output strides (1620, 3, 1) (1620, 3, 1)
As we'll see, this difference between the strides does in fact fully account for the 100x slowdown. Can we fix this? We can, but first, the post itself will need to seriously slow down to explain these strides, because they're so weird. And then we'll snatch our 100x right back from these damned strides.
numpy array memory layout
So, what's a "stride"? A stride tells you how many bytes you have to, well, stride from one pixel to the next. For instance,
let's say we have a 3D array like an RGB image. Then given the array base pointer and the 3 strides, the address of
array[x,y,z] will be base + x*xstride + y*ystride + z*zstride (where with images, z is one of 0, 1 or
2, for the 3 channels of an RGB image.)
In other words, the strides define the layout of the array in memory. And for better or worse, numpy is very flexible with respect to what this layout might be, because it supports many different stride values for a given array shape & datatype.
The two layouts at hand - numpy's default layout, and SDL's - are... well, I don't even know which of the two offends me
more. As you can see from the stride values, the layout numpy uses by default for a 3D array is
base + x*3*height + y*3 + z.
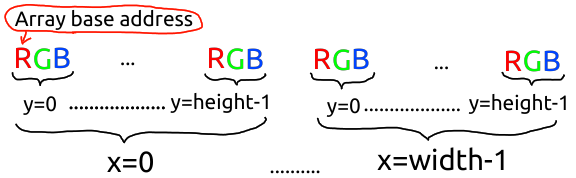
This means that the RGB values of a pixel are stored in 3 adjacent bytes, and the pixels of a column are stored contiguously in memory - a column-major order. And I, for one, find this offensive, because images are traditionally stored in a row-major order, in particular, image sensors send them this way (and capture them this way, as you can see from the rolling shutter - every row is captured at a slightly different time, not column.)
"Why, we do follow that respected tradition as well," say popular numpy-based image libraries. "See for yourself -
save an array of shape (1920, 1080) to a PNG file, and you'll get a 1080x1920 image." Which is true, and of course
makes it even worse: if you index with arr[x,y], then x, aka dimension zero, actually corresponds to the
vertical dimension in the corresponding PNG file, and y, aka dimension one, corresponds to the horizontal
dimension. And thus numpy array columns correspond to PNG image rows. Which makes the numpy image layout "row-major" in
some sense, at the cost of x and y having the opposite of their usual meaning.
...Unless you got your numpy array from a pygame Surface object, in which case x actually does index into the
horizontal dimension. And so saving pixels3d(surface) with, say, imageio will produce a transposed PNG
relatively to the PNG created by pygame.image.save(surface). And in case adding that insult to the injury
wasn't enough, cv2.resize gets a (width, height) tuple as the destination size, producing an output array of shape
(height, width).
Against the backdrop of these insults and injuries, SDL has an inviting, civilized-looking layout where x is x, y is y, and
the data is stored in an honest row-major order, for all the meanings of "row." But then upon closer look, the layout just
tramples all over my feelings: base + x*4 + y*4*width - z.
Like, the part where we have 4 in the strides instead of 3 as expected for an RGB image - I can get that part. We did ask for
an RGBA image, with an alpha channel, when we passed SRCALPHA to the Surface constructor. So I guess it
keeps the alpha channel together with the RGB pixels, and the 4 in the strides is needed to skip the As in RBGA. But then why,
may I ask, are there separate pixels3d and pixels_alpha functions? It's always annoying to have to
deal with RGB and alphas separately when using numpy with pygame surfaces. Why not a single pixels4d
function?..
But OK, the 4 instead of the 3 I could live with. But a zstride of -1? MINUS ONE? You start at the address of your Red pixel, and to get to Green, you walk back one byte?! Now you're just fucking with me.
It turns out that SDL supports both RGB and BGR layout (in particular, apparently surfaces loaded from files are RGB, and
those created in memory are BGR?.. or is it even hairier than this?..) And if you use pygame's APIs, you needn't worry about RGB
vs BGR, the APIs handle it transparently. If you use pixels3d for numpy interop, you also needn't worry
about RGB vs BGR, because numpy's flexibility with strides lets pygame give you an array that looks like RGB despite it
being BGR in memory. For that, z stride is set to -1, and the base pointer of the array points to the first pixel's red value -
two pixels ahead of where the array memory starts, which is where the first pixel's blue value is.
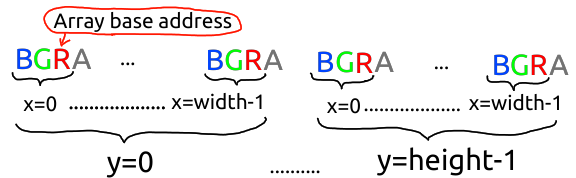
Wait a minute... now I get why we have pixels3d and pixels_alpha but no pixels4d!! Because SDL has
RGBA and BGRA images - BGRA, not ABGR - and you can't make BGRA data look like an RGBA numpy array, no matter what
weird values you use for strides. There's a limit to layout flexibility... or rather, there really isn't any limit beyond the
limits of computability, but thankfully numpy stops at configurable strides and doesn't let you specify a generic callback
function addr(base, x, y, z) for a fully programmable layout2.
So to support RGBA and BGRA transparently, pygame is forced to give us 2 numpy arrays - one for RGB (or BGR, depending on the surface), and another for the alpha. And these numpy arrays have the right shape, and let us access the right data, but their layouts are very different from normal arrays of their shape.
And different memory layout can definitely explain major differences in performance. We could try to figure out exactly why the performance difference is almost 100x. But when possible, I prefer to just get rid of garbage, rather than study it in detail. So instead of understanding this in depth, we'll simply show that the layout difference indeed accounts for the 100x - and then get rid of the slowdown without changing the layout, which is where "unsafe Python" finally comes in.
How can we show that the layout alone, and not some other property of the pygame Surface data (like the memory it's allocated
in) explains the slowdown? We can benchmark cv2.resize on a numpy array we create ourselves, with the same layout as
pixels3d gives us:
# create a byte array of zeros, and attach
# a numpy array with pygame-like strides
# to this byte array using the buffer argument.
i3 = np.ndarray((IW, IH, 3), np.uint8,
strides=(4, IW*4, -1),
buffer=b'\0'*(IW*IH*4),
offset=2) # start at the "R" of BGR
with Timer('pixels3d-like layout with cv2'):
for i in range(repeat):
o2 = cv2_resize(i3)
Indeed this is about as slow as we measured on pygame Surface data:
pixels3d-like layout with cv2 took 1.3829 sec
Out of curiosity, we can check what happens if we merely copy data between these layouts:
i4 = np.empty(i2.shape, i2.dtype)
with Timer('pixels3d-like copied to same-shape array'):
for i in range(repeat):
i4[:] = i2
with Timer('pixels3d-like to same-shape array, copyto'):
for i in range(repeat):
np.copyto(i4, i2)
Both the assignment operator and copyto are very slow, almost as slow as cv2.resize:
pixels3d-like copied to same-shape array took 1.2681 sec pixels3d-like to same-shape array, copyto took 1.2702 sec
Fooling the code into running faster
What can we do about this? We can't change the layout of pygame Surface data. And we seriously don't want to copy the C++ code of cv2.resize, with its various platform-specific optimizations, to see if we can adapt it to the Surface layout without losing performance. What we can do is feed Surface data to cv2.resize using an array with numpy's default layout (instead of straightforwardly passing the array object returned by pixel3d.)
Not that this would actually work with any given function, mind you. But it will work specifically with resizing, because it doesn't really care about certain aspects of the data, which we're incidentally going to blatantly misrepresent:
- Resizing code doesn't care if a given channel represents red or blue. (Unlike, for instance, converting RGB to greyscale, which would care.) If you give it BGR data and lie that it's RGB, the code will produce the same result as it would given actual RGB data.
- Similarly, it doesn't matter for resizing which array dimension represents width, and which is height.
Now, let's take another look at the memory representation of pygame's BGRA array of shape (width, height).
This representation is actually the same as an RGBA array of shape (height, width) with numpy's default strides!
I mean, not really - if we reinterpret this data as an RGBA array, we're treating red channel values as blue and vice versa.
Likewise, if we reinterpret this data as a (height, width) array with numpy's default strides, we're implicitly
transposing the image. But resizing wouldn't care!
And, as an added bonus, we'd get a single RGBA array, and resize it with one call to cv2.resize, instead of resizing pixels3d and pixels_alpha separately. Yay!
Here's code taking a pygame surface and returning the base pointer of the underlying RGBA or BGRA array, and a flag telling if it's BGR or RGB:
import ctypes
def arr_params(surface):
pixels = pg.surfarray.pixels3d(surface)
width, height, depth = pixels.shape
assert depth == 3
xstride, ystride, zstride = pixels.strides
oft = 0
bgr = 0
if zstride == -1: # BGR image - walk back
# 2 bytes to get to the first blue pixel
oft = -2
zstride = 1
bgr = 1
# validate our assumptions about the data layout
assert xstride == 4
assert zstride == 1
assert ystride == width*4
base = pixels.ctypes.data_as(ctypes.c_void_p)
ptr = ctypes.c_void_p(base.value + oft)
return ptr, width, height, bgr
Now that we have the underlying C pointer to the pixel data, we can wrap it in a numpy array with the default strides, implicitly transposing the image and swapping the R & B channels. And once we "attach" a numpy array with default strides to both the input and the output data, our call to cv2.resize will run 100x faster!
def rgba_buffer(p, w, h):
# attach a WxHx4 buffer to the base pointer
type = ctypes.c_uint8 * (w * h * 4)
return ctypes.cast(p, ctypes.POINTER(type)).contents
def cv2_resize_surface(src, dst):
iptr, iw, ih, ibgr = arr_params(src)
optr, ow, oh, obgr = arr_params(dst)
# our trick only works if both surfaces are BGR,
# or they're both RGB. if their layout doesn't match,
# our code would actually swap R & B channels
assert ibgr == obgr
ibuf = rgba_buffer(iptr, iw, ih)
# numpy's default strides are height*4, 4, 1
iarr = np.ndarray((ih,iw,4), np.uint8, buffer=ibuf)
obuf = rgba_buffer(optr, ow, oh)
oarr = np.ndarray((oh,ow,4), np.uint8, buffer=obuf)
cv2.resize(iarr, (ow,oh), oarr, interpolation=cv2.INTER_AREA)
Sure enough, we finally get a speedup instead of a slowdown from using cv2.resize on Surface data, and we're as fast as resizing an RGBA numpy.zeros array (where originally we benchmarked an RGB array, not RGBA):
osurf = pg.Surface((OW,OH), pg.SRCALPHA)
with Timer('attached RGBA with cv2'):
for i in range(repeat):
cv2_resize_surface(isurf, osurf)
i6 = np.zeros((IW,IH,4), np.uint8)
with Timer('np.zeros RGBA with cv2'):
for i in range(repeat):
o6 = cv2_resize(i6)
The benchmark says we got our 100x back:
attached RGBA with cv2 took 0.0097 sec np.zeros RGBA with cv2 took 0.0066 sec
All of the ugly code above is on GitHub. Since this code is ugly, you can't be sure it actually resizes the image correctly, so there's some more code over there that tests resizing on non-zero images. If you run it, you will get the following gorgeous output image:

Did we really get a 100x speedup? It depends on how you count. We got cv2.resize to run 100x faster relatively to calling it straightforwardly with the pixel3d array. But specifically for resizing, pygame has smoothscale, and our speedup relatively to it is 13-15x. There are some more benchmarks on GitHub for functions other than resize, some of which don't have a corresponding pygame API:
- Copying with
dst[:] = src: 28x - Inverting with
dst[:] = 255 - src: 24x cv2.warpAffine: 12xcv2.medianBlur: 15xcv2.GaussianBlur: 200x
So not "exactly" 100x, though I feel it's fair enough to call it "100x" for short.
In any case, I'd be surprised if that many people use SDL from Python for this specific issue to be broadly relevant. But I'd guess that numpy arrays with weird layouts come up in other places, too, so this kind of trick might be relevant elsewhere.
"Unsafe Python"
The code above uses "the C kind of knowledge" to get a speedup (Python generally hides data layout from you, whereas C proudly exposes it.) It also, unfortunately, has the memory (un)safety of C - we get a C base pointer to the pixel data, and from that point on, if we mess up the pointer arithmetic, or use the data after it was already freed, we're going to crash or corrupt data. And yet we wrote no C code - it's all Python.
Rust has an "unsafe" keyword where the compiler forces you to realize that you're calling an API which voids the normal safety guarantees. But the Rust compiler doesn't make you mark your function as "unsafe" just because you have an unsafe block in that function. Rather, it trusts you to decide whether your function is itself unsafe or not.
(In our example, cv2_resize_surface is a safe API, assuming I don't have a bug, because none of the horror
escapes into the outside world - outside, we just see that the output surface was filled with the output data. But
arr_params is a completely unsafe API, since it returns a C pointer that you can do anything with. And
rgba_buffer is also unsafe - although we return a numpy array, a "safe" object, nothing prevents you from
using it after the data was freed, for example. In the general case, no static analysis can tell whether you've built something
safe from unsafe building blocks or not.)
Python doesn't have an unsafe keyword - which is in character for a dynamic language with sparse static
annotation. But otherwise, Python + ctypes + C libraries is sort of similar in spirit to Rust with
unsafe. The language is safe by default, but you have your escape hatch when you need it.
"Unsafe Python" exemplifies a general principle: there's a lot of C in Python. C is Python's evil twin, or, in chronological order, Python is C's good-natured twin. C gives you performance, and doesn't care about usability or safety; if any of the footguns go off, tell it to your healthcare provider, C isn't interested. Python on the other hand gives you safety, and it's based on a decade's worth of research into usability for beginners. It doesn't, however, care about performance. They're both optimized aggressively for two opposite goals, at the cost of ignoring the other's goals.
But on top of that, Python was built with C extensions in mind from the start. Today, from my point of view, Python
functions as a packaging system for popular C/C++ libraries. I have way less appetite for downloading and building OpenCV
to use it from C++ than pip installing OpenCV binaries and using them from Python, because C++ doesn't have a
standard package management system, and Python does. There are a lot of high-performance libraries (for instance in scientific
computing and deep learning) with more code calling them in Python than in C/C++. And on the other hand, if you want seriously
optimized Python code and a small deployment footprint / low startup time, you'd use Cython to
produce an extension "as if written in C" to spare the overhead of an otherwise "more Pythonic" JIT-based system like numba.
Not only is there a lot of C in Python, but, being opposites of sorts, they complement each other fairly well. A good way to make Python code fast is using C libraries in the right ways. Conversely, a good way to use C safely is to write the core in C and a lot of the logic on top of it in Python. The Python & C/C++/Rust mix - either a C program with a massive Python extension API, or a Python program with all of the heavy lifting done in C - seems quite dominant in high-performance, numeric, desktop / server areas. And while I'm not sure this fact is very inspiring, I think it's a fact3, and things will stay this way for a long time.
Thanks to Dan Luu for reviewing a draft of this post.