We're living in the golden age of hardware design – it probably won't get any cheaper to make a new chip. Yes, there's the downside that it's harder to be wildly incompatible with everything than in the old days – there's plenty of standard interfaces to support. On the other hand, it's a benefit, not just a drawback – make a chip with a CPU that runs C, an Ethernet controller and a DRAM interface, and it's now usable with plenty of software and hardware developed by others.
And then for the wilder, "incompatible" innovations – if you really want to invent interfaces and not just implementations – there's the "accelerator" realm: an MPEG decoder, a DSP, a GPU. A decade ago, they said that "standard" microprocessors killed all high-performance architectures. Today, a system that kept the "fastest computer in the world" title for almost a year is based on GPUs – and "non-standard"/"incompatible" accelerators are everywhere (not to mention SIMD instruction set extensions right inside the otherwise "compatible"/"commodity" CPUs).
Still, while it indeed became way cheaper to make your own chips since you don't have to erect your own fab to do that, "cheap" still means costs somewhere in the millions – not quite what the word "cheap" brings to mind. And mistakes still can't be corrected, not really. Which results, among other things, in an understandable risk aversion with respect to design.
A language geek, who's naturally curious about programming languages that don't look mainstream (C with classes), is going to meet many such languages, and plenty of implementations to play with. A hardware geek, who's equally curious about designs that don't look mainstream (RISC/VLIW with bells and whistles), is going to find few such designs and very few implementations. Risk aversion is innovation aversion.
APA thus combines two traits that are rare – it gets at least 9 out of 10 in the "non-mainstream" category, and implementations were actually manufactured and shipped, specifically, in early smartphones by NeoMagic (BDTI and EETimes articles are some of the architecture overviews). The phones apparently weren't very successful, but it seems a poor measure of the architecture's merit in this case, just because there are so many ways to fail regardless of your accelerator quality. So the platform's demise gives us not evidence but a lack of evidence (the platform wasn't widely targeted by 3rd party developers whose opinions could be interesting).
Overview
APA stands for Associative Processing Array, a kind of content-addressable memory. Just memory. How do you compute
using just memory? 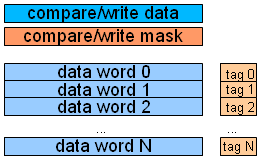 The operations are done right there, near the cells where your bits are kept. No need
to read your data word by word into a processor, than write it back – rather, your operations run in parallel, inside the
memory, on every data word! SIMD operations on steroids.
The operations are done right there, near the cells where your bits are kept. No need
to read your data word by word into a processor, than write it back – rather, your operations run in parallel, inside the
memory, on every data word! SIMD operations on steroids.
What operations? Bitwise operations – masked compare and masked write:
- Compare:
tag[i] = (word[i]&mask)==(compare_data&mask) - Write:
if(tag[i]) word[i]=(word[i]&mask) | (write_data&~mask)
...where a tag bit is kept for every data word (row), and mask & compare/write data are broadcasted to all rows. You can also move words – either to the adjacent rows or to rows at distance 8 (or, say, 16, depending on the hardware configuration – but not at an arbitrary distance). And you can move the data in or out, sequentially.
Where's the code – who decides what to write, compare and move in what order? One option is to use a low-end CPU running "normal" code to control the contents of the compare/write data & mask registers, to issue APA operations and to interact with the host system (the "real" CPU and external memory). This little processor isn't "accelerating" computations by itself, just controls the APA accelerator hardware.
That's it. No add, no multiply, no nothing. How's that for non-mainstream?
So, how do you actually do anything with this SIMD-on-steroids machine – say, add two vectors of numbers? Well, you need to have both vectors in the array – each element pair occupying some of the bits of a row (for instance, the NeoMagic 512-row APA had 160 bits per row, so for 16 bit vectors, you'd use 32 bits out of 160). Then you perform the addition bit by bit, using masked compare and write operations.
That's right, addition done entirely in software. Latency: 48 cycles for 16 bits, throughput: >10 16b additions/cycle for NeoMagic's 512-row APA. More latency for 32 bits, less for 8 bits, still less for 3 bits. Which means optimization opportunities you're not used to having in software (you gain no speed-up using only 3 bits of a 32b CPU register for addition). On the other hand, it means large penalties for high precision (floating point takes thousands of cycles).
Tools and libraries would be supplied with an APA implementation, but the exciting thought for a programmer is to be able to bypass them where needed and get down to bit-level manipulation! (The exciting thought for a decision maker would be to always use the tools, never pay someone for the bit fiddling; well, different people get their excitement from different things.)
Pros & cons
In a way, it's an exceedingly generic and elegant architecture, and a very impressive one. One "gets it" like one doesn't get any other. Just try to describe any other sort of programmable machine to a level of detail sufficient for accurate predictions about performance.
Surprisingly – or, perhaps, unsurprisingly given just how unusual this machine is – I simultaneously also don't get it like any other. I'm not used to thinking of computations that way, both in terms of precision and in terms of data access. I have no idea what share of my 8-bit numbers only have just 5 or 2 bits and it can matter a lot here.
Likewise, even for algorithms that don't require random access – and APA is simply not good for random access – I have little idea of just how non-random my access is. That is, similarly to the precision case where constants I'm not used to care about matter, there's a difference between accessing a row at distance 1 and a row at distance 5, and I don't know how frequent different distances between adjacent things are in a code base I care about.
So while in the abstract, a shorter than ever architecture description is sufficient here for accurate performance predictions, I lack intuition and experience that would make such predictions easy.
A great thing about the APA design is its "hardware friendliness". The typical processor design involves a truckload of convoluted circuits that are likeable for their function, but unimaginable to the human mind as physical objects – so cumbersome, infinitely configurable, finicky tools are used to translate a functional description of said circuits to actual electric circuits occupying actual space.
The typical hardware design is not hardware friendly (sounds strange – but the average piece of software isn't very considerate towards its target processor and software stack, either). The APA, on the other hand, has a natural spatial mapping with its 2 dimensions (row bit width and the number of rows) and regular connections between just the adjacent or relatively close rows.
Again, surprisingly – or unsurprisingly given how unusual the APA is – this is also a drawback, in the sense that the standard hardware design tools will do a very poor job implementing APA. For that matter, standard tools will likely do an even worse job implementing plain RAM – which also has a natural spatial mapping and regular structure.
RAM is analog design, not digital: rather than describing it on a functional level, someone implements it as a physical circuit description. Basically, RAM is a library for digital tools, like flip-flops or simple gates – a library that can't be implemented using the tool itself.
I really appreciate the von Neumann architecture, but it's scary to realize just how strong the von Neumann grip really is. RAM is basically the only interface to a large array of bits that is relatively easily accessible to a hardware designer. (Not that it's very easily accessible, mind you – there is no portable interface for RAM, believe it or not, but no matter how you build your chips, you'll be able to get some sort of RAM).
What happens if you want your own bag of bits instead of RAM? You can do what they call full custom design – make your own physical circuit description. This isn't "portable", where "porting" means changing the manufacturing process – either to move from 65nm to 40nm, or from one manufacturer to another. It's also a longer and more complicated process. But it's certainly doable, especially if you outsource it to the inventors, as you'd have to do anyway because the thing is patented.
The hostility to hardware design tools (despite the friendliness to the basic constraints of hardware) and patent protection make APA more of a possible off-the-shelf solution than inspiring source of ideas, and so does the design simplicity. Unlike, say, VLIW, which is a design style with basic ideas in the public domain and countless possible variations and extensions (starting with the "let's add this one spiffy instruction" variety), APA is more or less complete. There are important constants to tweak – row width and the distance to easily accessible neighbors – but while it could be a hard choice to make, it's not very creative. (I do believe it could be a source of ideas if only through expanding one's horizons, which is why I write about it.)
If we attempt to discuss the efficiency of APA qualitatively, in terms of hardware resource utilization rather than throughput per mm^2 or per mW for a given app, three things come to mind:
- Benefit - a perennial bottleneck of accessing memory through a bus very narrow compared to the amount of bits stored is eliminated. This "ought to be good" for algorithms where access is "far from random" since these gain nothing from conventional RAM's flexibility but pay the full price of its low throughput.
- Drawback - the cycle is "wasted": values are read from flip-flops, undergo very few transformations and are written back. This "ought to be bad" because it won't translate to high frequency (you can't read then write a flip-flop very fast – and doing this with them all at once dissipates power, so in fact low frequencies enabled by parallelism, not high frequencies enabled by circuit simplicity are APA's potential advantage in the frequency department). A competing design running at a similar frequency, however, will do much more per cycle (like actual addition) because circuits implementing combinatorial logic are fast. The question thus becomes how big those circuits are compared to flip-flops: if enough APA rows can be packed instead, the throughput will still be competitive despite the abysmal latency – provided that you simultaneously process sufficiently large amounts of data.
- Benefit - ability to use DRAM cells. This "ought to be good" since DRAM cells are much smaller than normal flip-flops (which is achieved through having them leak their charge so they have to be periodically refreshed). AFAIK, nobody uses them for computation directly because they don't fit in traditional hardware models – neither as registers (that's plain dumb) nor as local RAM (they have poor latency and imply a cumbersome controller to access as a RAM). An APA, on the other hand, could potentially run well on DRAM cells if the required simple circuitry were implemented near the cells. One problem with this is that custom chips may be easy to make these days, but not custom DRAM chips. In particular, Andy Glew, formerly from Intel then AMD, said at some place that it's "hard to influence DRAM makers", and if it's hard for Intel or AMD, well, it's probably hard in general.
Overall, I have a lot of reservations here – not just because of the way originality by itself seems to complicate matters here (I'd hate to admit it as the only reason...), but because it's a step in the opposite direction to what successful SIMD systems are doing. That is, you get high throughput given unusually low precision and unusually restricted data access patterns. A DSP from the late 90s would attempt to process numbers with more bits and would let you fetch them from more places. A GPU from the 2000s still more so – floating point numbers, parallel random access with transparent contention handling (at least in CUDA GPUs). It seems that the direction is removing restrictions on the set of things you run fast, not very high throughput for a very restricted set.
On the other hand, there exist algorithms with low precision and high locality. And it's exciting to see an architecture which is not RAM-based, naturally represented in space, etc. – all those things which get people excited in hardware discussions – but practical enough for a real world delivery, and with some things connecting it to more usual programming models (for instance, SIMD commands broadcasted from a CPU instead of clever local rules you have no idea how to come up with as in cellular automata). So it's definitely very interesting.
Update: as a better informed commenter pointed out, APA is also known as CAPP – Content Addressable Parallel Processor, and implementations date as early as 1972 (which makes you wonder what could legitimately remain outside the public domain by now). This seems an evidence of having failed the test of time – or having some really deep trouble with commercialization. I'd be curious to hear a software developer's experience with this – BDTI's article from 2003 talked about the development experience in hypothetical terms and entirely in the future tense, whereas some past evidence has to be available.