Once a chip’s single-core performance lags by more than a factor to two or so behind the higher end of current-generation commodity processors, making a business case for switching to the wimpy system becomes increasingly difficult.
– Google's Urs Hölzle, in "Brawny cores still beat wimpy cores, most of the time"
Google sure knows its own business, so they're probably right when they claim that they need high serial performance. However, different businesses are different, and there are advantages to "wimpy cores" beyond power savings which are omitted from the "brawny/wimpy" paper and which are worth mentioning.
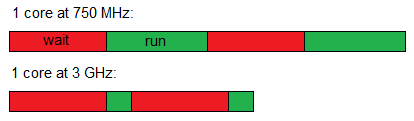
It is a commonplace assumption that a single 3 GHz processor is always better than 4 processors at 750 MHz "because of Amdahl's law". Specifically:
- Some of your tasks can be parallelized to run on 4 cores – these will take the same time to complete on the two systems.
- Other tasks can only run on one core – these will take 4x more time to complete on the 750 MHz wimpy-core system.
- Some tasks are in-between – say, a task using 2 cores will take 2x more time to complete on the 750 MHz system.
Overall, the 3 GHz system never completes later and sometimes completes much earlier.
However, this assumes that a 3 GHz processor is consistently 4x faster than a 750 MHz processor. This is true in those rare cherished moments when both processors are running at their peak throughput. It's not true if both are stuck waiting for a memory request they issued upon a cache miss. For years, memory latency has been lagging behind memory throughput, and the 4x faster processor does not get a 4x smaller memory latency.
Assuming the latency is the same on the two systems – which is often very close to the truth – and that half of the time of the 750 MHz system is spent waiting for memory when running a serial task, the 3 GHz CPU will give you a speed-up of less than 2x.
What if the task can run in parallel on 4 cores? Now the 750 MHz system gets a 4x speed-up and completes more than 2x faster than the 3 GHz system!
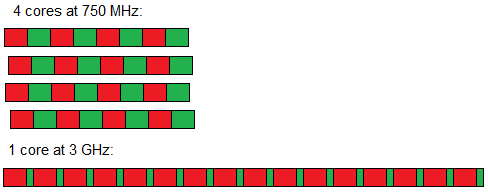
(This assumes that the 4 750 MHz cores are not slowed down due to them all accessing the same memory – which, again, is very close to the truth. Memory bandwidth is usually high enough to serve 4 streams of requests – it's latency which is the problem. So having several cores waiting in parallel is faster than having one core waiting serially.)
A slow, parallel system outperforming a fast, serial system – Amdahl's law in reverse!
Is memory latency unique?
In a way it isn't – there are many cases where faster systems fail to get to their peak throughput because of some latency or other. For instance, the cost of mispredicted branches will generally be higher on faster systems.
However, most other latencies of these kinds are much smaller – and are handled rather well by the mechanisms making "brawny" cores larger and deserving of their name. For example, hardware branch predictors and speculative execution can go a long way in reducing the ultimate cost of mispredicted branches.
"Brawny" speculative hardware is useful enough to deal with memory latency as well, of course. Today's high-end cores all have speculative memory prefetching. When you read a contiguous array of memory, the core speculates that you'll keep reading, fetches data ahead of the currently processed elements, and when time comes to process the next elements, they're already right there in the cache.
The problem is that this breaks down once you try to use RAM as RAM - a random access memory where you don't go from index 0 to N but actually "jump around" randomly. (Theoretically this isn't different from branch prediction; in practice, large, non-contiguous data structures not fitting into caches and "unpredictable" for prefetchers are much more common than unpredictable branches or overflowing the branch history table.)
Hence we have pledges like this computer architect's kind request to stop using linked lists:
Why would anyone use a linked-list instead of arrays? I argue that linked lists have become irrelevant in the context of a modern computer system:
They reduce the benefit of out-of-order execution.
They throw off hardware prefetching.
They reduce DRAM and TLB locality.
They cannot leverage SIMD.
They are harder to send to GPUs.
Note that problems 1, 2 and 4 "disappear" on wimpy cores – that is, such cores don't have out-of-order execution, hardware prefetchers or SIMD instructions. So a linked list doesn't result in as many missed performance opportunities as it does on brawny cores.
"Why would anyone use linked lists"? It's not just lists, for starters – it's arrays of pointers as well. "Why array of pointers" seems exceedingly obvious – you want to keep references instead of values to save space as well as to update something and actually get the thing updated, not its copy. Also you can have elements of different types – very common with OO code keeping arrays of base class pointers.
And then using arrays and indexing into them instead of using pointers still leaves you with much of the "access randomness" problem. A graph edge can be a pointer or an index; and while mallocing individual nodes might result in somewhat poorer locality than keeping them in one big array, you still bump into problems 1, 2 and 4 for big enough node arrays – because your accesses won't go from 0 to N.
Of course you could argue that memory indirection is "poor design" in the modern world and that programmers should mangle their designs until they fit modern hardware's capabilities. But then much of the "brawny vs wimpy" paper's argument is that brawny cores mean smaller development costs – that you get high performance for little effort. That's no longer true once the advice becomes to fight every instance of memory indirection.
It's also somewhat ironic from a historical perspective, because in the first place, we got to where we are because of not wanting to change anything in our software, and still wishing to get performance gains. The whole point of brawny speculative hardware is, "your old code is fine! Just give me your old binaries and I'll magically speed them up with my latest and greatest chip!"
The upshot is that you can't have it both ways. Either keep speculating (what, not brawny/brainy enough to guess where the next pointer is going to point to?), or admit that speculation has reached its limits and you can no longer deliver on the promises of high serial performance with low development costs.
Formalizing "reverse Amdahl's law"
...is not something I'd want to do.
Amdahl's law has a formal version where you take numbers representing your workload and you get a number quantifying the benefits a parallel system might give you.
A similar formalization could be done for "reverse Amdahl's law", taking into account, not just limits to parallelization due to serial bottlenecks (what Amdahl's law does), but also "limits to serialization"/the advantage to parallelization due to various kinds of latency which is better tolerated by parallel systems.
But I think the point here is that simple formal models fail to capture important factors – not that they should be made more complex with more input numbers to be pulled out of, erm, let's call it thin air. You just can't sensibly model real programs and real processors with a reasonably small bunch of numbers.
Speaking of numbers: is time spent waiting actually that large?
I don't know; depends on the system. Are there theoretically awesome CPUs stuck waiting for various things? Absolutely; here's that article about 6% CPU utilization in data servers (it also says that this is viewed as normal by some – as long as RAM and networking resources are utilized. Of course, by itself the 6% figure doesn't mean that brawny cores aren't better – if those 6% are all short, serial sprints letting you complete requests quickly, then maybe you need brawny cores. The question is how particular tasks end up being executed and why.)
Could a "wimpy-core" system improve things for you? It depends. I'm just pointing out why it could.
From big.LITTLE to LITTLE.big, or something
There's a trend of putting a single wimpy core alongside several brawny ones, the wimpy core being responsible for tasks where energy consumption is important, and the brawny ones being used when speed is required.
An interesting alternative is to put one brawny core and many wimpy ones – the brawny core could run the serial parts and the wimpy cores could run the parallel parts. If the task is serial, then a brawny core can only be better – perhaps a lot better, perhaps a little better, but better. If the task is parallel, many wimpy cores might be better than few brawny ones.
(I think both use cases fall under ARM's creatively capitalized "big.LITTLE concept"; if the latter case doesn't, perhaps LITTLE.big could be a catchy name for this – or we could try other capitalization options.)
Hyperthreading/Barrel threading/SIMT
...is also something that helps hide latency using coarse-grain, thread-level parallelism; it doesn't have to be "whole cores".
Parallelizing imperative programs
...is/can be much easier and safer than is commonly believed. But that's a subject for a separate series of posts.
Summary
- Faster processors are exactly as slow as slower processors when they're stalled – say, because of waiting for memory;
- Many slow processors are actually faster than few fast ones when stalled, because they're waiting in parallel;
- All this on top of area & power savings of many wimpy cores compared to few brawny ones.